
Distribuciones de Probabilidad
Los Números Primos y Los sistemas Complejos
El mundo de los números siempre tiene particularidades por conocen. Dejo para ustedes una particularidad sobre cierta regularidad de los números primos que se analiza desde una distribución estadística, por medio de la ley de Benford..
En matemáticas, un número primo es un número natural mayor que 1 que tiene únicamente dos divisores distintos: él mismo y el 1. Los números primos se contraponen así a los compuestos, que son aquellos que tienen algún divisor natural aparte de sí mismos y del 1. El número 1, por convenio, no se considera ni primo ni compuesto.
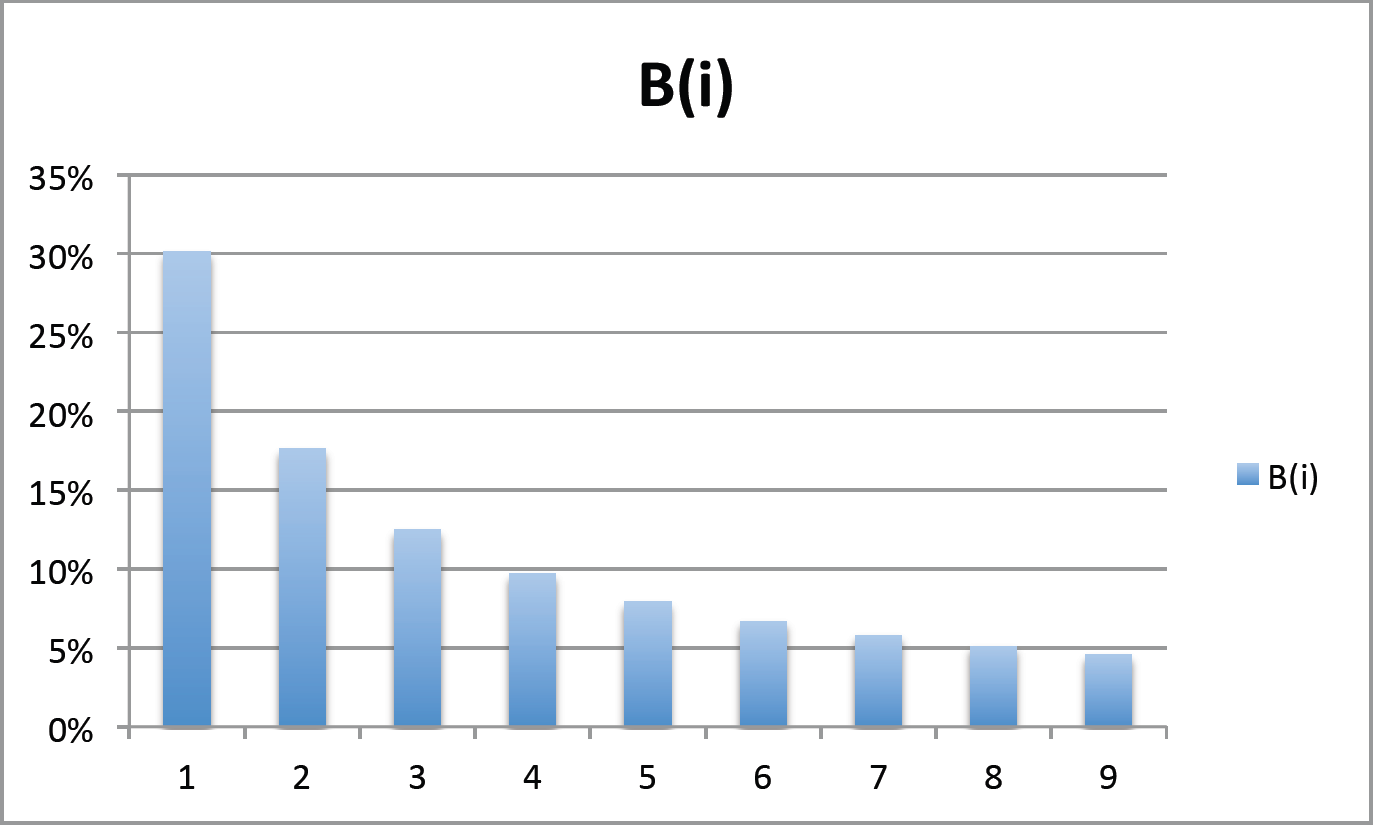
La ley de Benford, también conocida como la ley del primer dígito, asegura que, en los números que existen en la vida real, la primera cifra es 1 con mucha más frecuencia que el resto de los números. Además, según crece este primer dígito, más improbable es que se encuentre en la primera posición.
Más precisamente la ley de Benford establece que la primera cifra no nula n (n = 1, ..., 9) ocurre con una probabilidad igual a ( log10(n + 1) − log10(n) ), o
| Primera cifra | Probabilidad |
|---|---|
| 1 | 30.1 % |
| 2 | 17.6 % |
| 3 | 12.5 % |
| 4 | 9.7 % |
| 5 | 7.9 % |
| 6 | 6.7 % |
| 7 | 5.8 % |
| 8 | 5.1 % |
| 9 | 4.6 % |
Podemos formular una ley para las dos primeras cifras: la probabilidad de que las dos primeras cifras no nulas sean igual a n (n = 10, ..., 99) es igual a ( log10(n+1) − log10(n) ).
De un modo similar se puede enunciar una ley para las tres primeras cifras, para las cuatro primeras cifras, etc.
Gráficamente:
Para finalizar dejamos para ustedes un vídeo instructivo sobre este tema
